As someone who has been deeply involved in integrating LLMs into real-world use cases — both as an individual contributor and as a Tech Lead responsible for my team’s output — I consider myself reasonably knowledgeable on a practical level. Despite this, I am constantly baffled by the speed of progress in this field.
Just a few months ago, the state-of-the-art implementation for integrating LLMs into voice services looked like this:
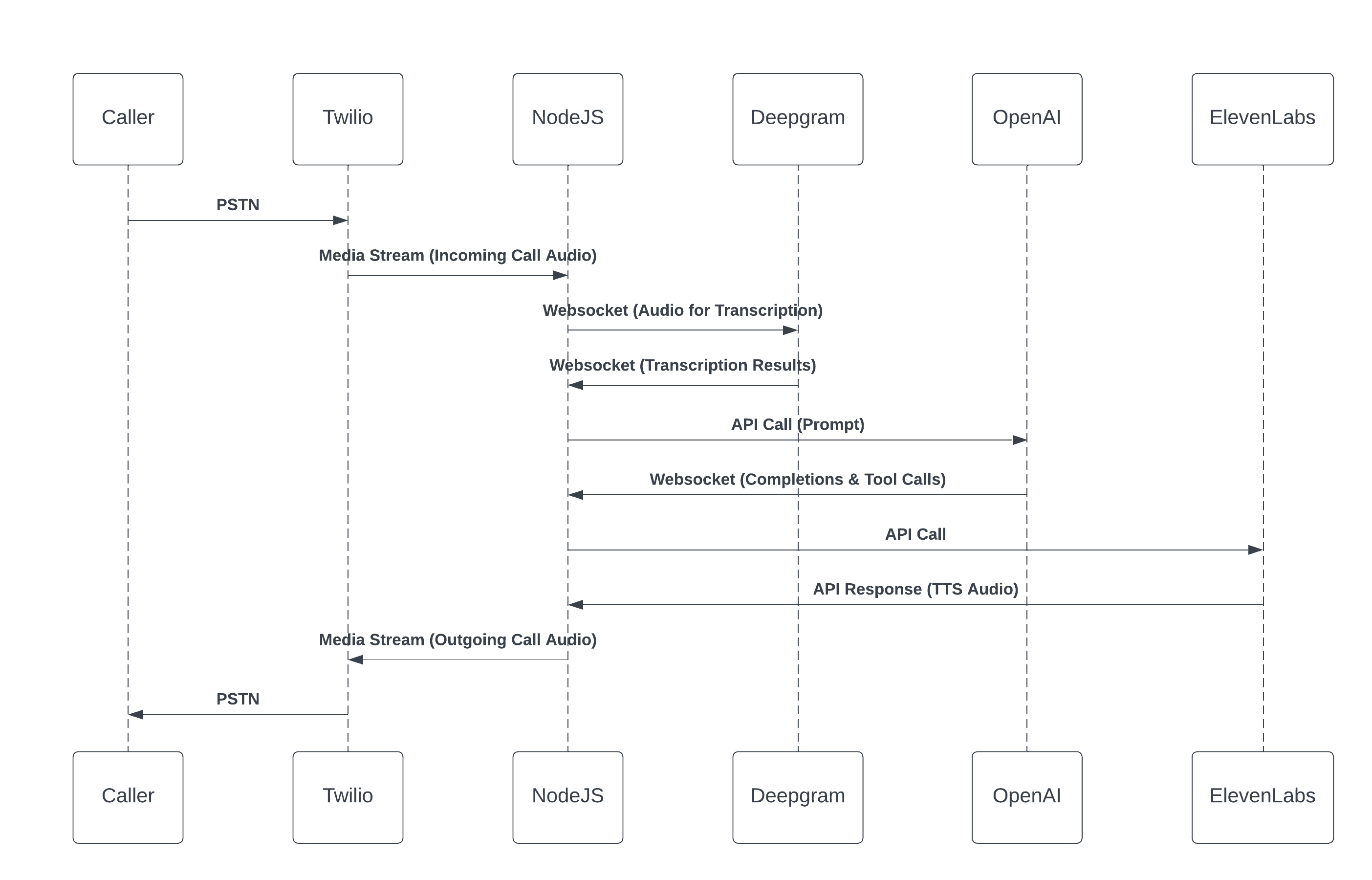
In simplified terms, voice presented significant challenges — several magnitudes higher — as, traditionally, LLMs required a text input. So how can we work with a sound input?
The classic approach involved a multi-step process:
-
Voice-to-Text (VTT): Convert the audio input to text.
-
Text Processing: Send the transcribed text to the LLM for inference.
-
Text-to-Speech (TTS): Convert the LLM’s output back into audio for the user.
While this method “worked,” those steps introduced several major downsides:
-
Latency: The decoupled steps increased the overall response time, making interactions sluggish.
-
Language Limitations: VTT systems typically required specifying the input language beforehand for optimal transcription. Many well-known models at the time struggled with accuracy across multiple languages, making a truly multilingual bot impossible.
-
Context Window Constraints: For instance, at the time, OpenAI models were restricted to a 4KB context window, severely limiting the ability to provide personalized experiences. (Now the model
gpt-4o-2024-08-06has a total context window of 128k)
Fast forward to today. Where are we?
Today we don't need those intermediary steps at all, as now more and more models are capable of receiving an audio stream directly, and responding back on the same medium.
The first example you might have heard of, was the OpenAI Real Time API, released on October 1, 2024. Link
To quote their release notes:
Previously, to create a similar voice assistant experience, developers had to transcribe audio with an automatic speech recognition model like Whisper, pass the text to a text model for inference or reasoning, and then play the model’s output using a text-to-speech model. This approach often resulted in loss of emotion, emphasis and accents, plus noticeable latency. [...] The Realtime API improves this by streaming audio inputs and outputs directly, enabling more natural conversational experiences.
This was absolutely mind blowing. A true game changer.
Now, just an handful of months later, we have a bunch of contenders: some from Big Tech, namely Google with their Multimodal API, and a rich multitude of Startups and individual developers chiming in, each proposing their own implementation.
How does this architecture looks like on a high level? The Google one looks like this:
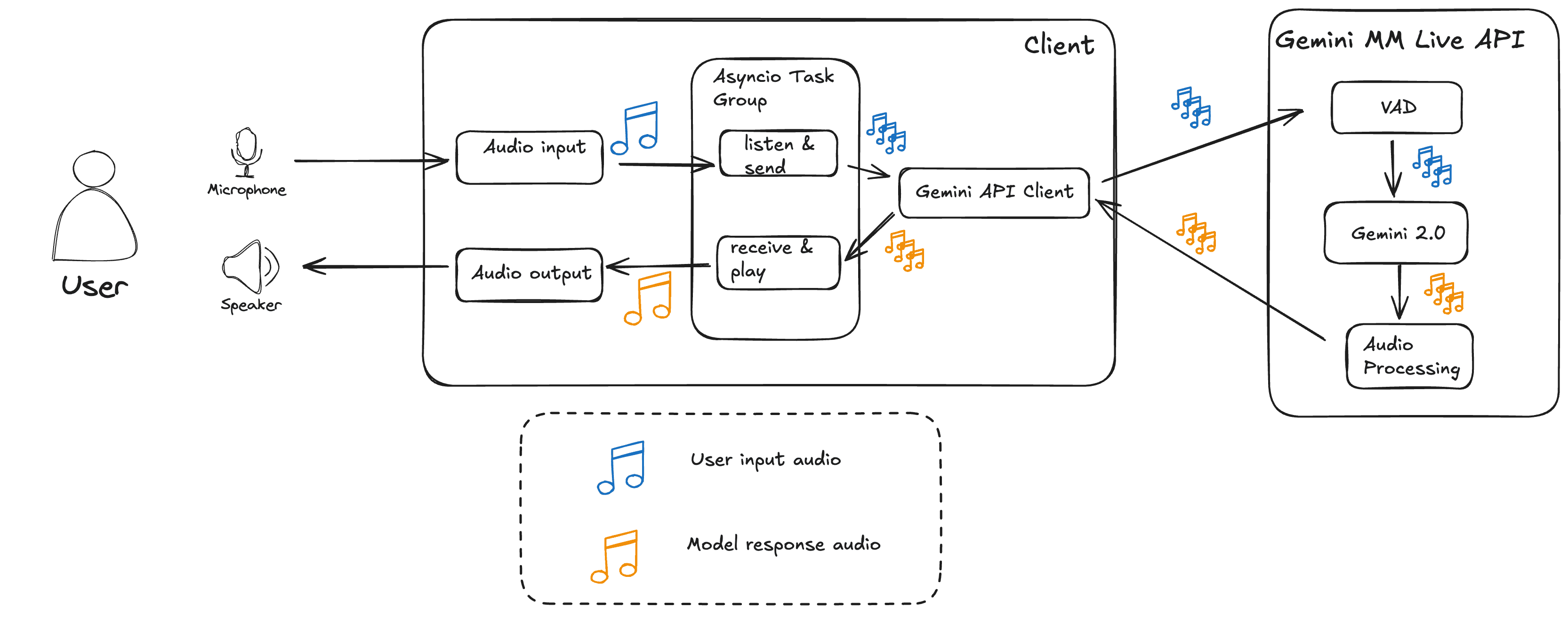
What is the secret sauce that makes this all possible? In one word: websockets This technology allows low-latency, two sided communication between clients and servers, enabling an interaction that is both seamless and real-time.
Remember the context window limitation? No longer a problem now, as we can now write functions on the Assistant's code, allowing the LLM to dynamically retrieve the context as needed. A much gentler approach from a FinOPS point of view as well, as a smaller context window means less context tokens, and also a lesser burden on whatever infrastructure is on the other end of those APIs you might want to plug on a bot.
That all sounds awesome but... where is the catch? Well... as of now those APIs tend to be on the pricy side as they need to run on very expensive GPUs and, obviously, companies are trying to repay their investment.
The good news is that those models are getting more and more powerful and efficient by the day, that means they are less and less computational hungry and so you can already run some of those models on even a M1 Pro chip, which is a laptop chip!
Stay tuned, I will likely post more about the topic. Reach out on LinkedIn if you want to chat!